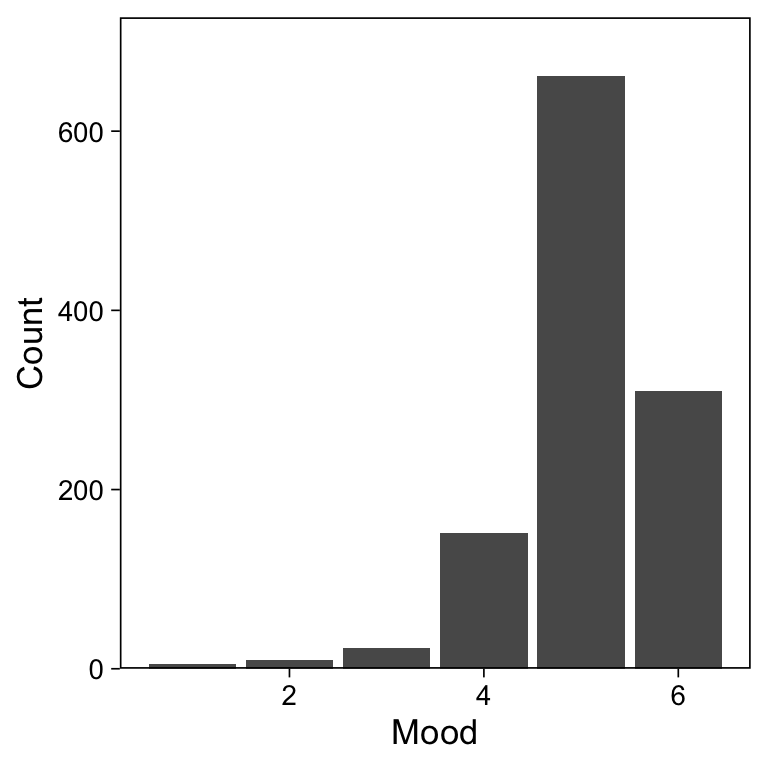
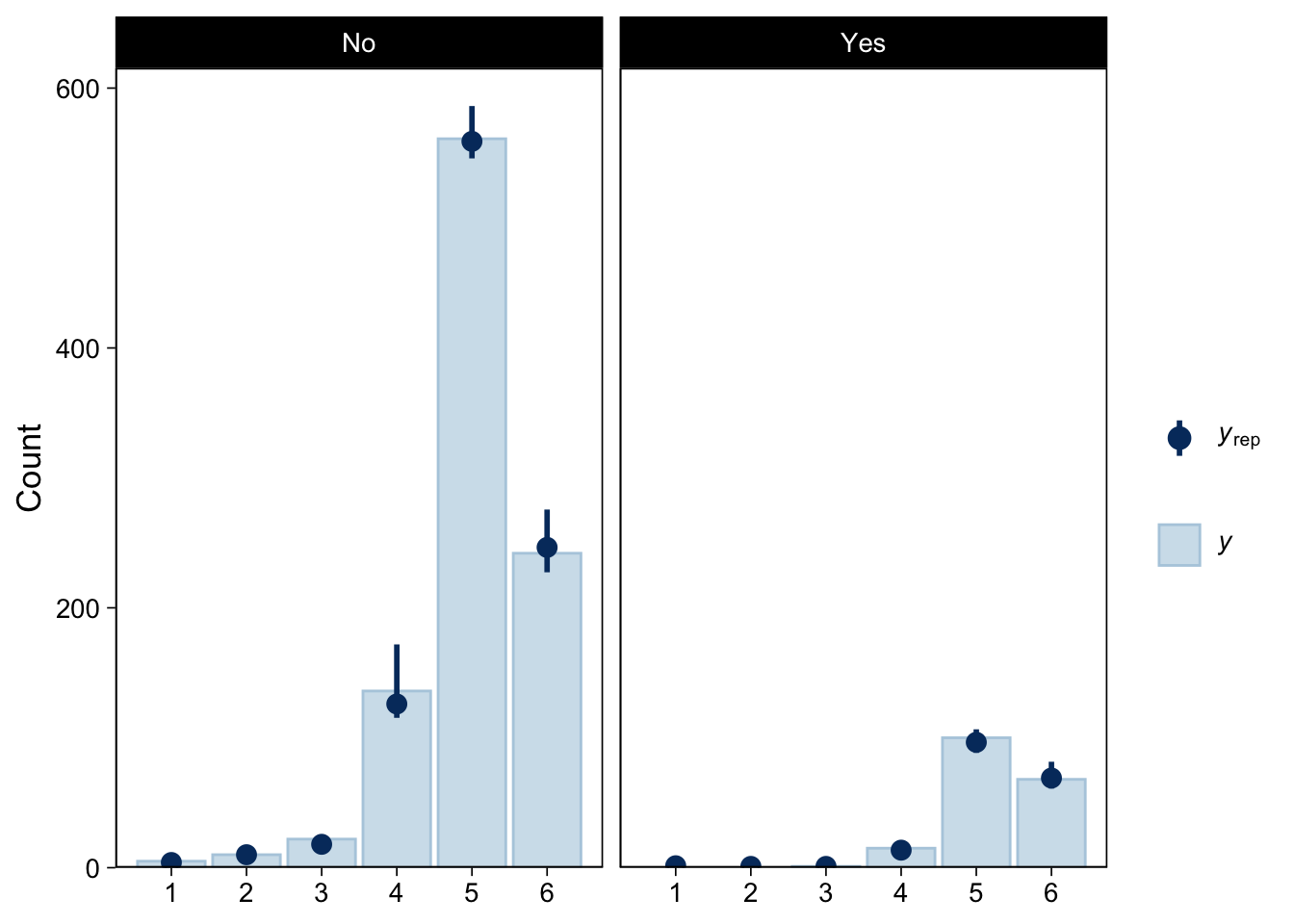
1,225 festivalgoers were asked about their mood, substance use, degree of experiencing a “transformative experience”
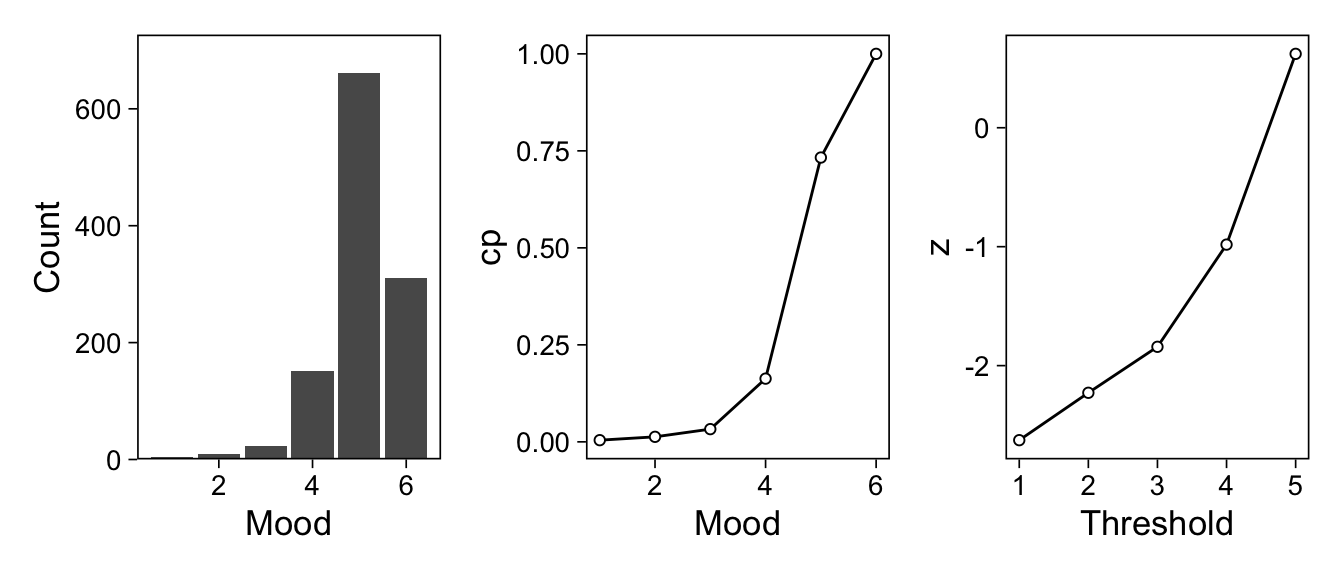
The mood rating item, \(Y\), had \(K + 1 = 6\) categories \(1, 2, ..., 6\)
Code
head(dat) |>kable()
mood
te
gender
age
survey
h24
5
3
1
30
Event3
0
5
2
2
50
Event5
0
6
7
1
32
Event4
0
6
7
2
33
Event2
0
5
1
1
22
Event3
0
5
7
2
22
Event4
0
Table 1: First six rows of data from Forstmann et al. (2020).
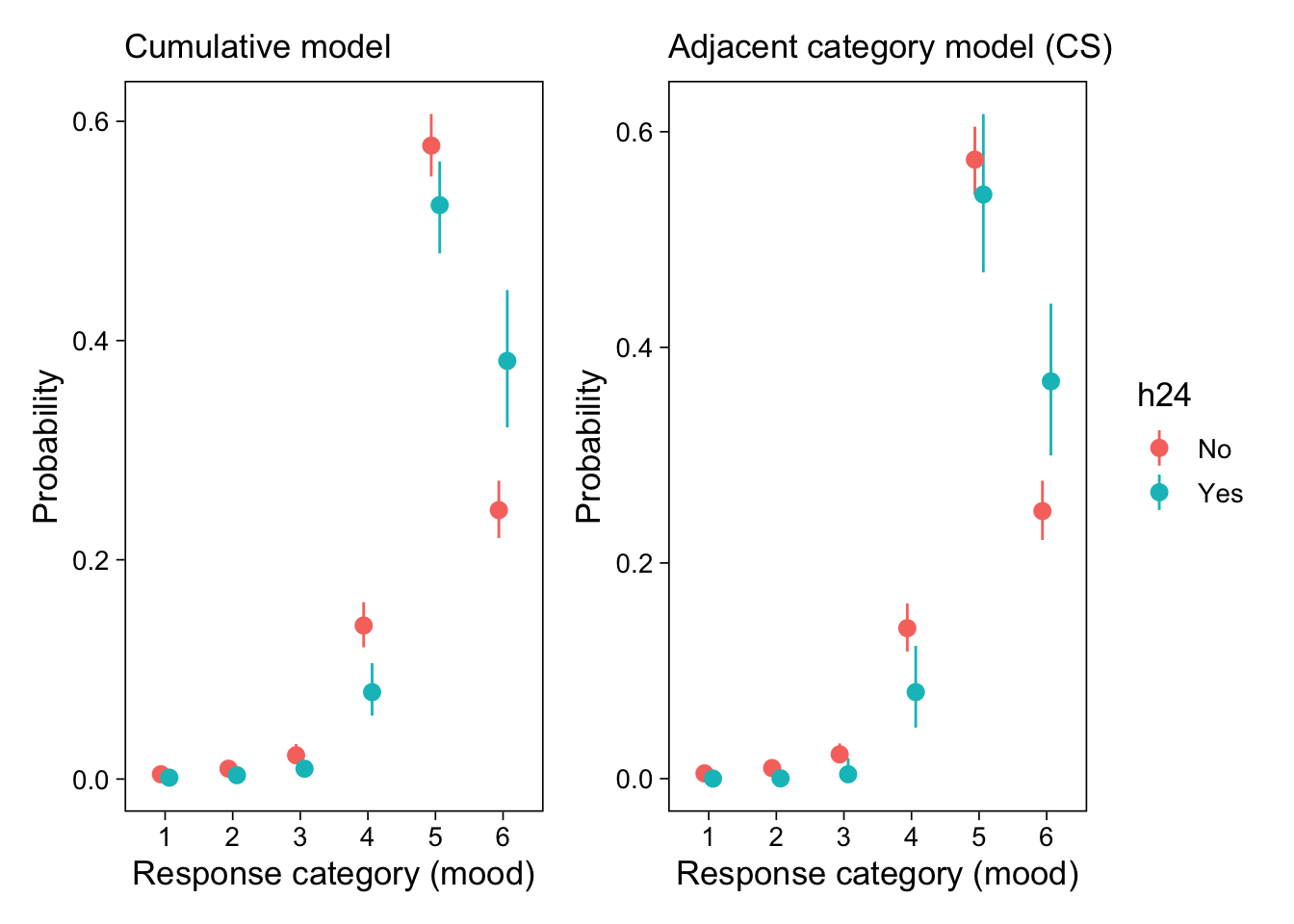
Cumulative model
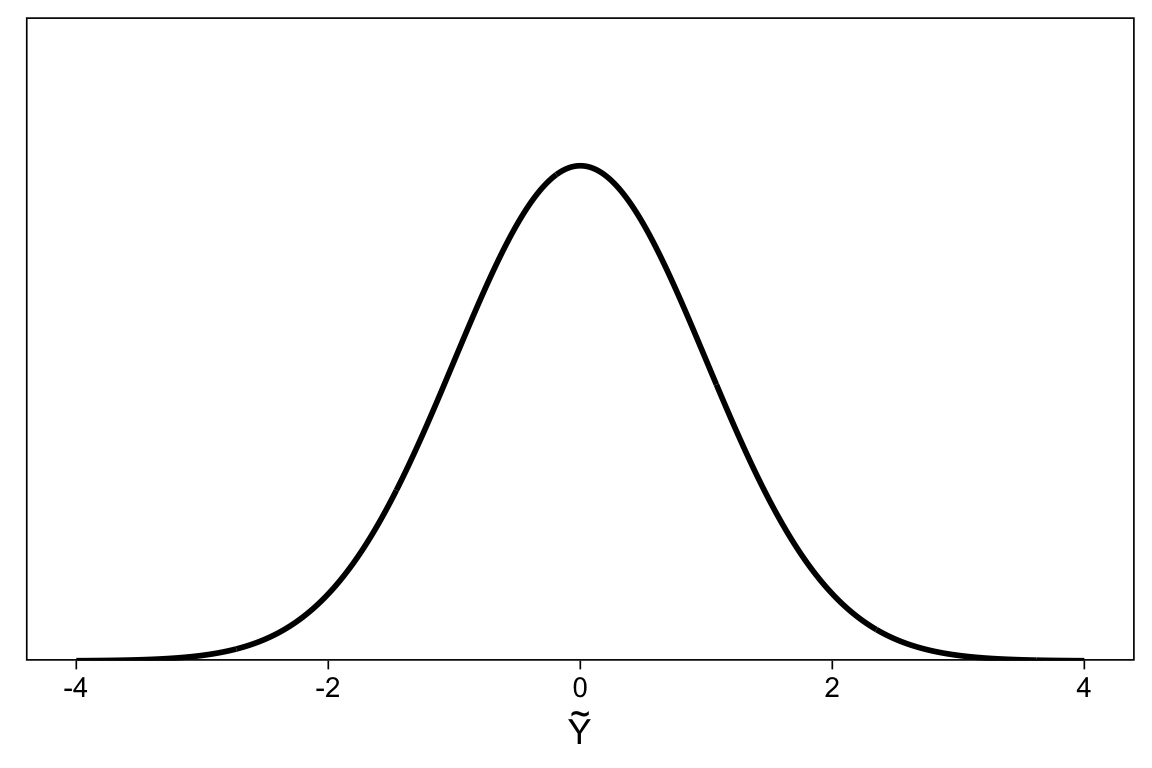
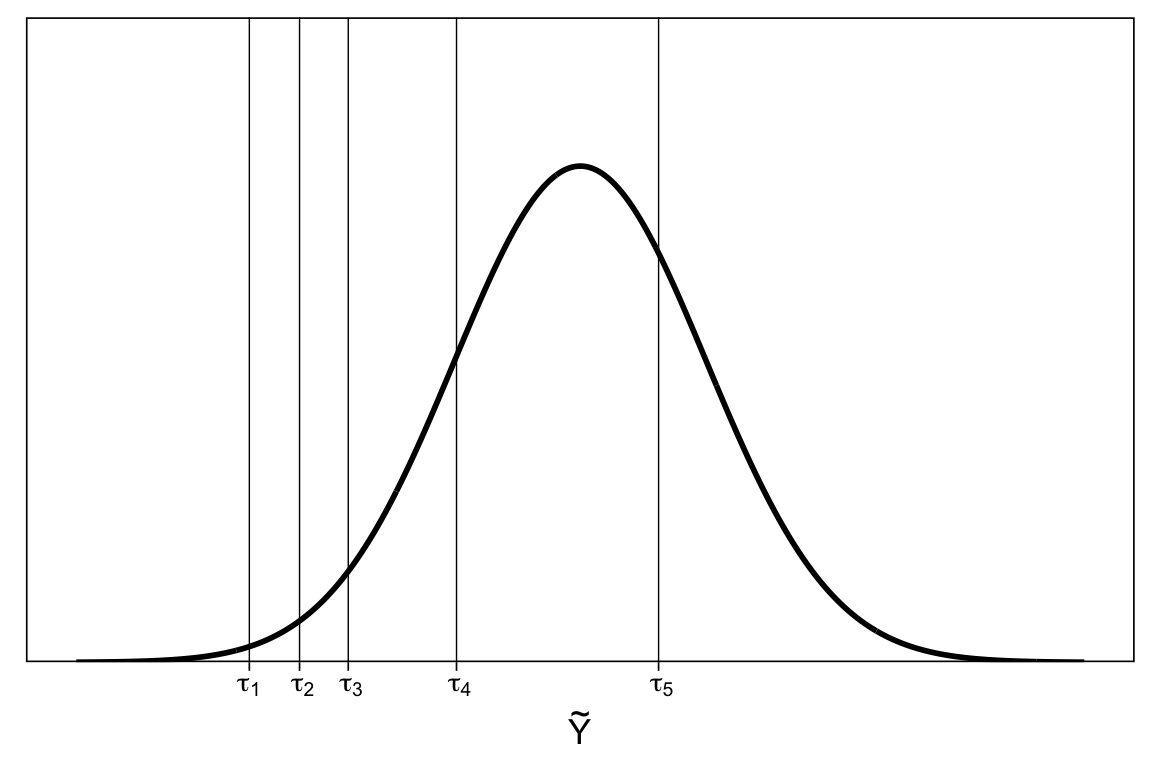
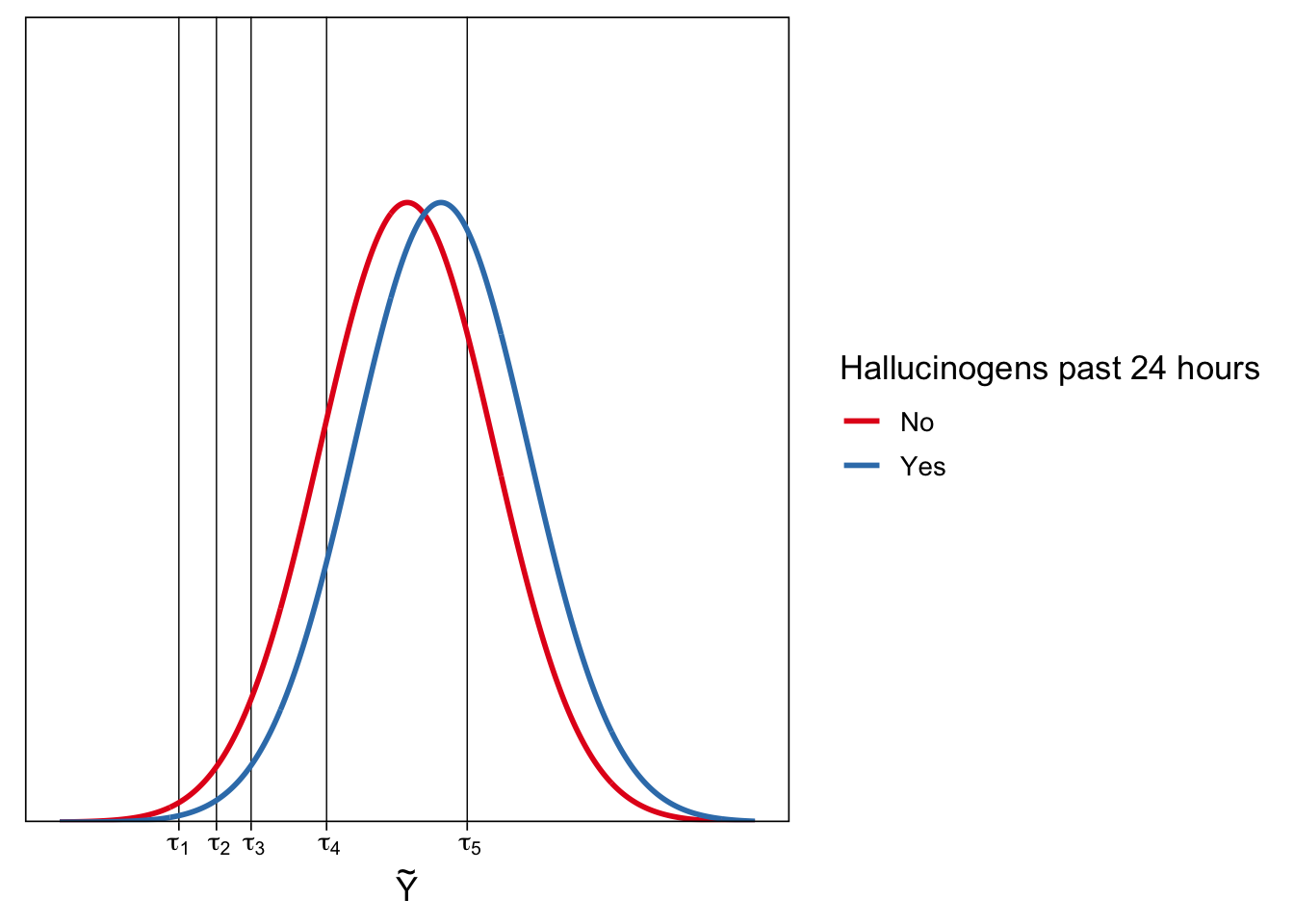
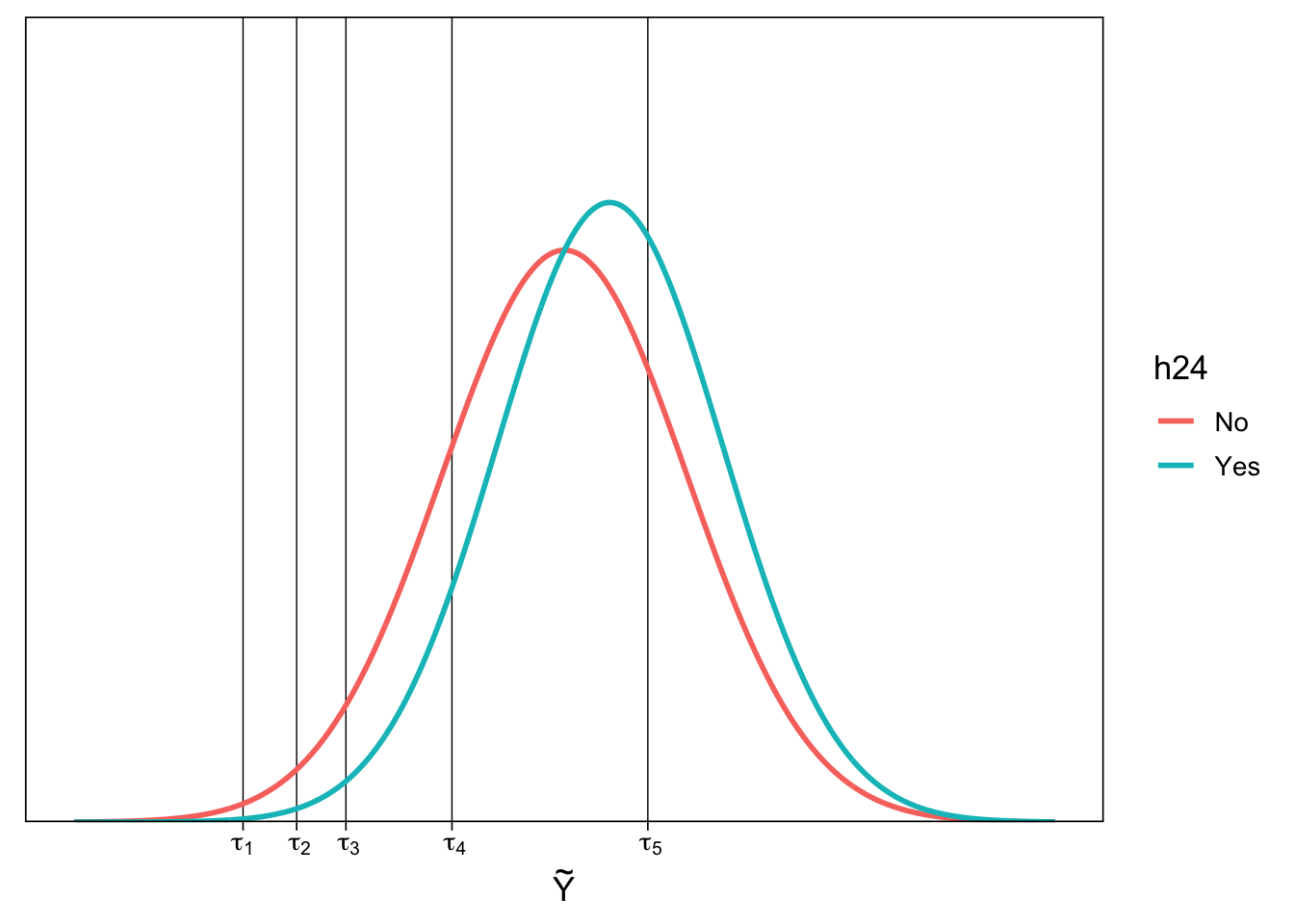
CM assumes that the observed categorical variable \(Y\) is based on the categorization of an unobserved (“latent”) variable \(\tilde{Y}\) with \(K\) thresholds \(\tau = (\tau_1, \dots, \tau_k)\).
In this example, \(\tilde{Y}\) has a natural interpretation as current mood
We assume that \(\tilde{Y}\) has a normal distribution, but other choices are possible, such as (default) logistic
Describe the ordered distribution of responses using thresholds
\(Y = k \Leftrightarrow \tau_{k-1} < \tilde{Y} \leq \tau_k\)
These thresholds give the probability of each response category
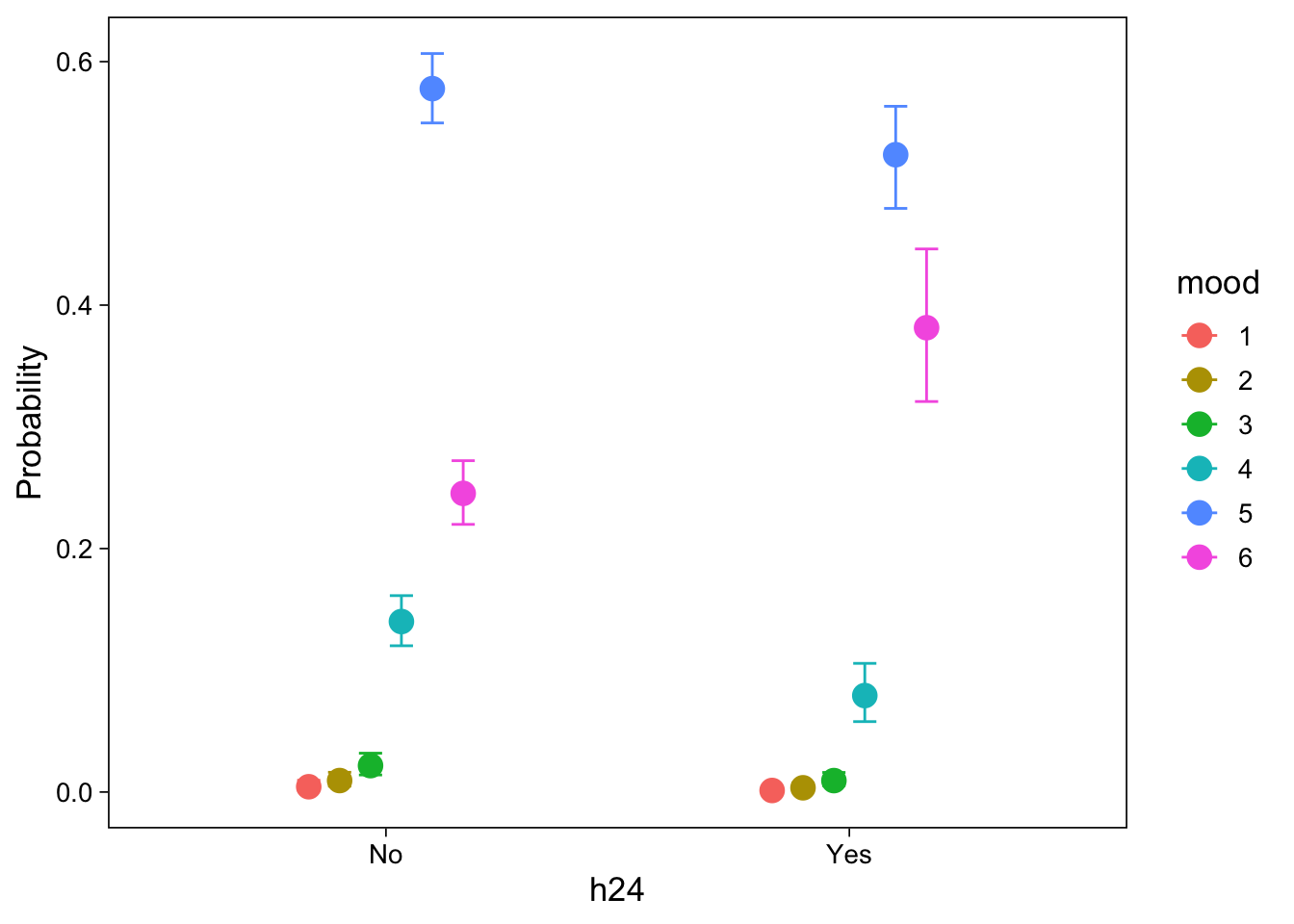
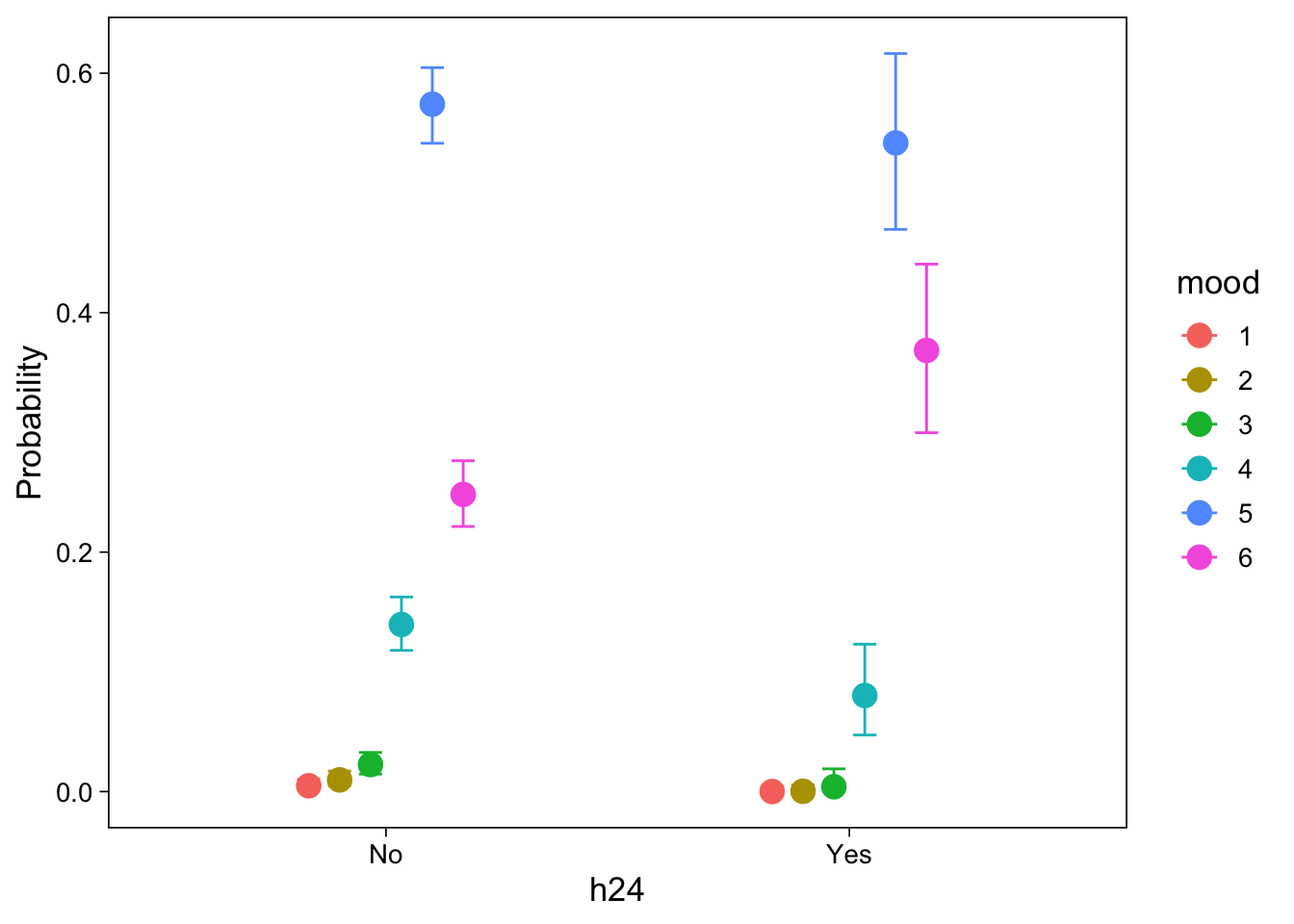
\(Pr(Y = k) = \Phi(\tau_k) - \Phi(\tau_{k-1})\)
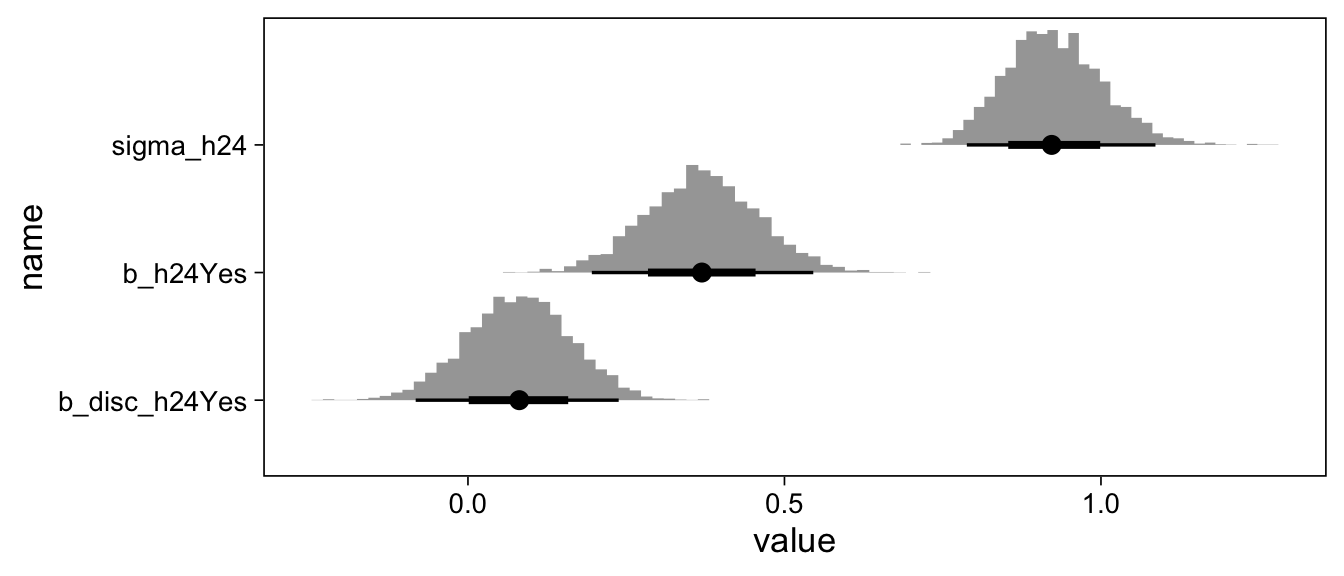
\(\tilde{Y}\) is amenable to regression (without intercept)
The weird link function and intercepts were difficult
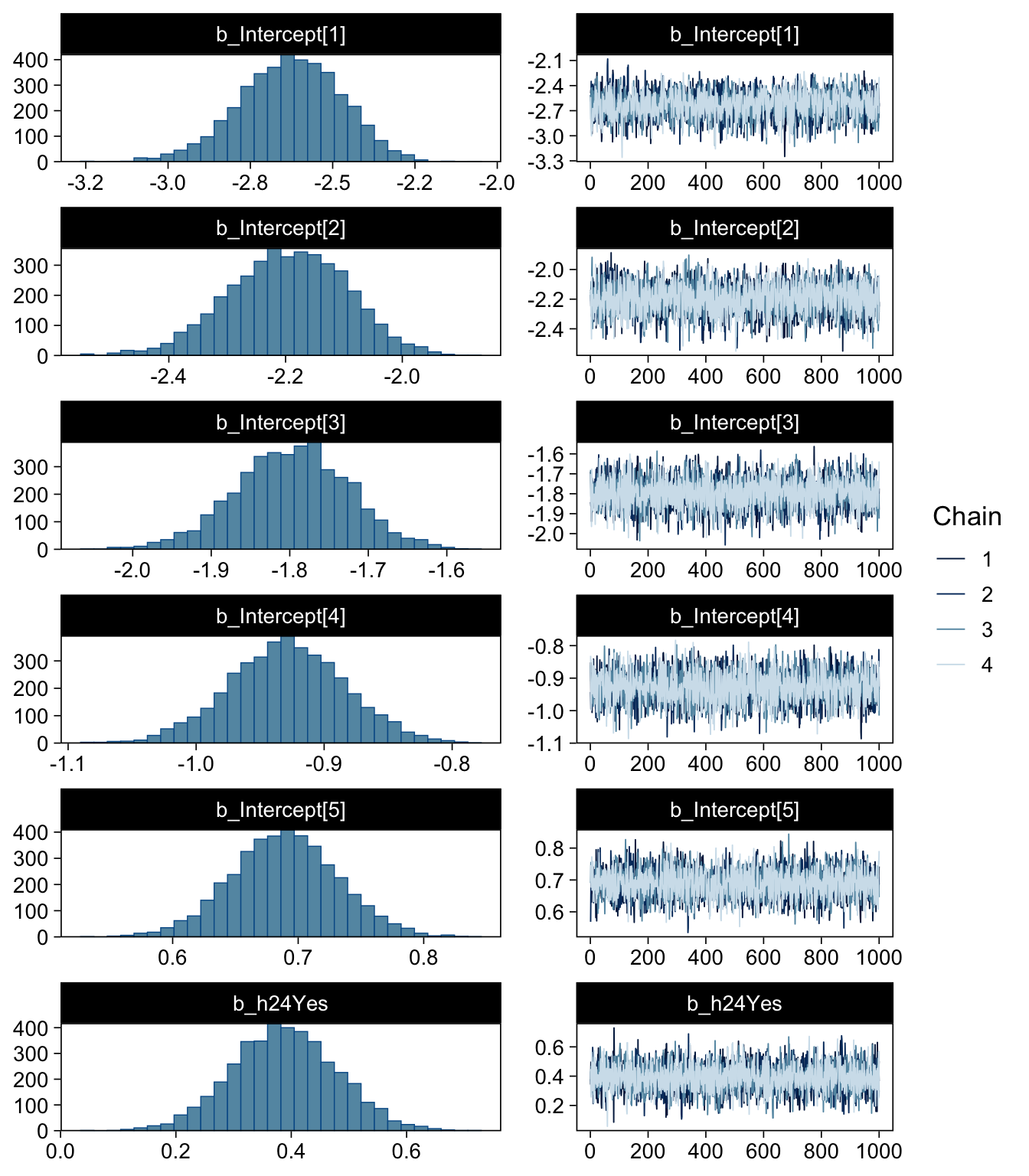
Effects on latent variable are interpretable just like your betas in lm()
The results are the same anyway
How do you know?
Did you fit an ordinal model to confirm?
The prevalence of problems in metric models applied to ordinal data is an empirical questions, and results probably vary greatly between types of data & measures
Fit ordinal models whenever you can
Afford more nuanced interpretation of what’s going on in your data
Multilevel model
So far…
We did not consider variability in mood beyond hallucinogen use
Bürkner, Paul-Christian, and Matti Vuorre. 2019. “Ordinal Regression Models in Psychology: A Tutorial.”Advances in Methods and Practices in Psychological Science 2 (1): 77–101. https://doi.org/10.1177/2515245918823199.
Forstmann, Matthias, Daniel A. Yudkin, Annayah M. B. Prosser, S. Megan Heller, and Molly J. Crockett. 2020. “Transformative Experience and Social Connectedness Mediate the Mood-Enhancing Effects of Psychedelic Use in Naturalistic Settings.”Proceedings of the National Academy of Sciences 117 (5): 2338–46. https://doi.org/10.1073/pnas.1918477117.
Liddell, Torrin M., and John K. Kruschke. 2018. “Analyzing Ordinal Data with Metric Models: What Could Possibly Go Wrong?”Journal of Experimental Social Psychology 79 (November): 328–48. https://doi.org/10.1016/j.jesp.2018.08.009.